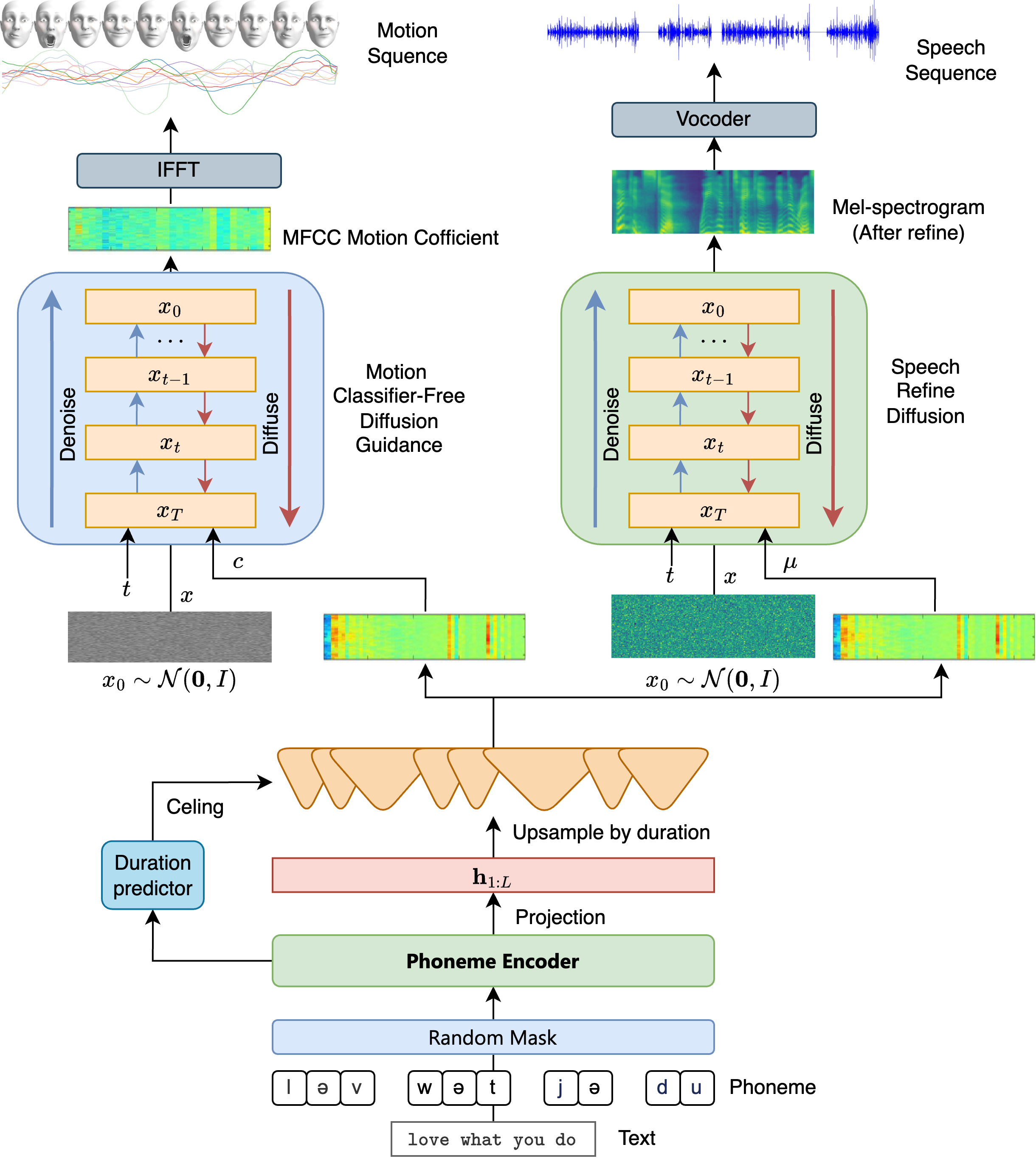
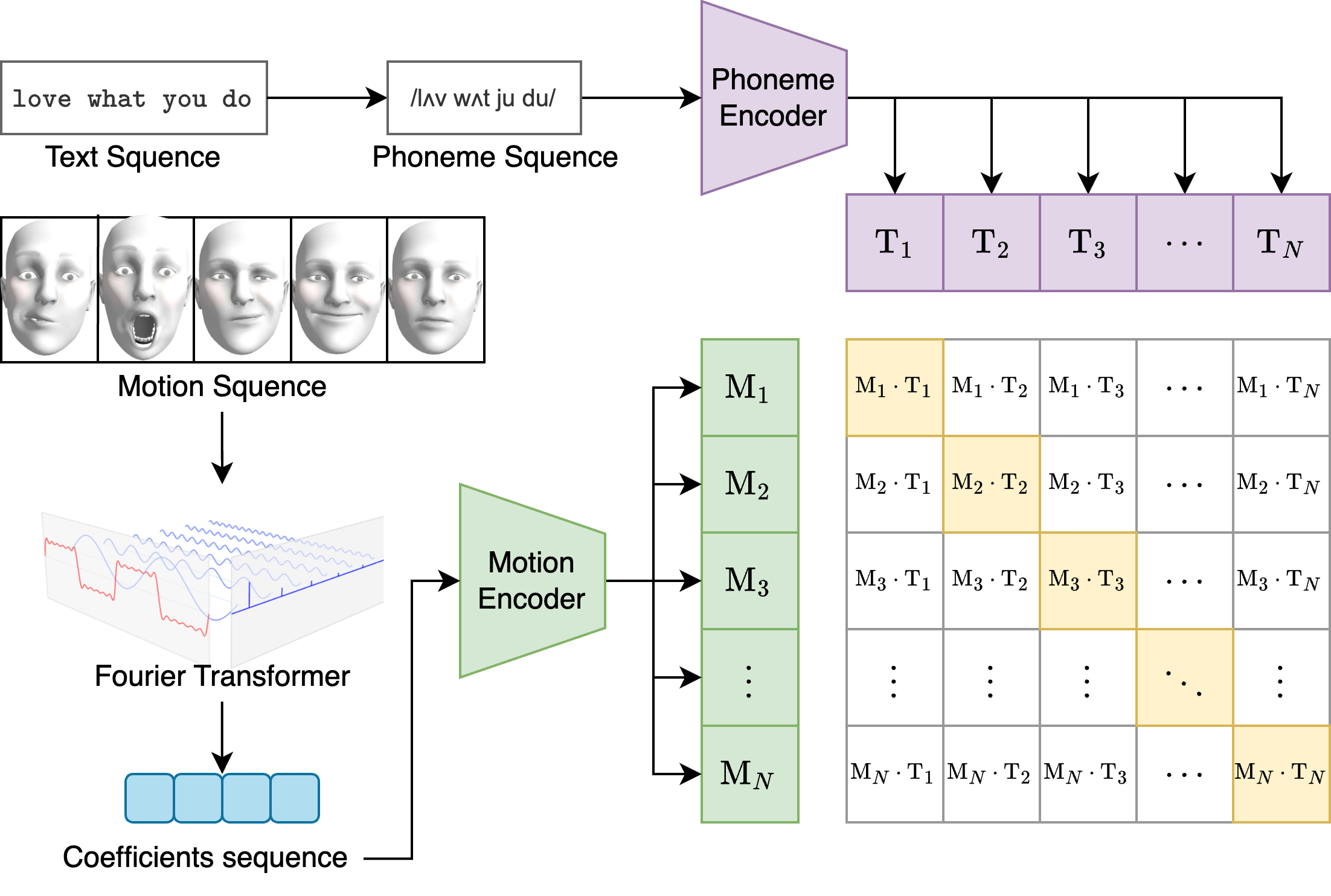
Realistic facial animation requires precise control of muscle movement, particularly when synthesizing speech-related expressions. While the Facial Action Coding System (FACS) has been widely used for emotion-driven facial control, it is not optimized for speech articulation. In this work, we introduce DeepPACS, a Phoneme Animation Coding System designed to provide a structured, interpretable, and controllable representation of facial movements induced by phonemes. DeepPACS learns a low-dimensional code for each frame aligned with phoneme input, which is then mapped to high-dimensional blendshape weights using a trainable parametric decoder. This coding system serves as a compact and semantically meaningful interface between phoneme sequences and facial animation, enabling both real-time inference and cross-domain applications such as TTS-driven avatars and digital humans. We evaluate DeepPACS on a blendshape-annotated 3D facial motion dataset, demonstrating superior performance over direct phoneme-to-blendshape regression baselines, while preserving smoothness, realism, and interpretability. Our framework also opens the path toward unified speech-gesture modeling by decoupling phonetic content from expressive modulation.